二分木
 | 「B木」とは異なります。 |
二分木(にぶんぎ)は、データ構造の1つである。二進木(にしんぎ)やバイナリツリー(英: binary tree)とも呼ばれ、根付き木構造の中で、全てのノード(節点 node)が持つ子の数が高々2であるものをいう。典型的には2つの子はそれぞれ「左」「右」と呼ばれる。
以後、括弧の中は英語表記。
用語
親から子へ有向線分(辺、エッジ edge)が引かれる。子を持たないノードを葉(リーフ leaf)ないし外部ノード (external node) と呼ぶ。葉でないノードを内部ノード (internal node) と呼ぶ。あるノードの「深さ」(depth) はルート(root 「根」にあたるノード)からそのノードまでにたどる経路(パス path)の長さ(経路の種類ではなく、ノード-ノードを1と数えた数)である。特定の「深さ」のノードを総称して木の中での「レベル」(level) と称することがある。あるノードの「高さ」 (height) はそのノードから最も遠い葉までの経路の長さである。同じ親を持つノード同志を兄弟 (siblings) であると呼ぶ。ノードpからノードqまでの経路がある場合、pはqの「先祖」(ancestor)、qはpの「子孫」(descendant) である。ノードの「大きさ」(size) は(自分自身を含んだ)そのノードの子孫の数である。
種類
二分木の中でも、全てのノードが「葉であるか、二つの子を持っている(次数が2であるという)」ものを、全二分木 (full binary tree) と呼ぶ。完全二分木 (perfect binary tree, complete binary tree) は全ての葉が同じ「深さ」を持つ二分木を指す。
Complete binary treeには他の定義もあり、ある n について、全ての葉が n または n-1 の「深さ」を持ち、全ての葉をできるだけ左に寄せた二分木を指すこともある。この場合、一番「下」のレベルは左側から全て連続的に埋まっていなければならない。
「ほとんど完全な二分木」(almost complete binary tree) は右である子がいれば必ず左である子がいるが、逆は必ずしも真でないものをいう。
グラフ理論での定義
典型的には次のような定義が用いられる。「二分木は連結された (connected) 閉路をもたない (acyclic) グラフで、各頂点 (vertex) の次数 (degree) (各頂点に出入りする辺の数)が3を超えないもの。」 次のことが証明可能である。いかなる二分木でも、次数1のノードの数(葉にあたる)は次数3であるノードの数よりちょうど2だけ多く、次数2であるノードはいかなる数にもなりうる。根付き二分木は、「根にあたる頂点が一つだけ決められており、各頂点の次数が2を超えないもの」をいう。
そのような根を一つ選ぶと、全ての頂点が各々ユニークな親と2つ以下の子を持つことになる。だがこれだけでは子供の左右を決めることができない。連結条件をはずしたもの(閉路をもたない無向グラフ)を森 (forest) と呼ぶ。森は木と異なり、互いに連結している要素が複数あってもよい。
もう一つの定義は有向グラフ上での再帰的定義である。二分木は次のいずれかを指す:
- 単一の頂点
- 二つの二分木 a, b と一つの頂点vを用意し、頂点vから二つの二分木a, bそれぞれの根に対して辺を引いたもの。
この定義では左右は決まらないが、唯一の根を決定することはできる。
データの二分木への格納法

二分木はプログラミング言語の基本的な要素を用いて構築することができる。データ型としてレコード型とポインタ型(参照型)をもったプログラミング言語では、典型的な方法では、何らかのデータと左右の子へのポインタからなるノードを組み合わせて木を構成する。場合によっては親へのポインタを用意することもある。参照する相手がない(左右どちらかあるいは両方の子がない)場合は、「何も参照していない」ことを示す特別な値 nil(nullのこと) にしておくか、事前に決めたあるノード(番兵と呼ぶ)を指すようにする。親への参照付きのデータ構築例をPascalによって示す。
type
pNode = ^Node; {ノード型へのポインタ}
Node = record
data : (* 必要なデータをためる部分 *)
left, parent, right : pNode
{左の子、親、右の子へのポインタ}
end;
...
var root, newnode : pNode;
...
begin
new(root); root^.parent := nil;
{根を植える。根には親がいない}
new(newnode); {新しいノードをつくる}
with newnode^ do begin
left := nil; right := nil; {子はいない}
parent := root {rootが親}
end;
root^.left := newnode; {左側の子に}
new(newnode); {新しいノードをつくる}
with newnode^ do begin
left := nil; right := nil; {子はいない}
parent := root {rootが親}
end;
root^.right := newnode {右側の子に}
...
明示的な方法ではないが、配列に二分木を格納する方法もある。完全二分木ならば、この方法でもスペースを無駄にすることはない。根の添字を0とすると、この場合、添字 i のノードの子は添字 2i + 1 と 2i + 2 に格納され、そのノード自体の親は(あれば)添字 floor((i-1)/2) にある。配列を用いると記憶容量の節約になり、行きがけ順(先行順、preorder traversal)でデータを舐める場合特に参照の局所性が向上する。しかし、連続したメモリ空間を必要とし、木が大きくなる際に大きな処理時間を必要とする。また n 個のノードを持つ高さ h の木に対し、2h - n に比例したメモリを消費する。

MLのようなタグ付き共有体を備えた言語では、しばしばタグ付き共有体として二分木は構築される。それには二種類のノードが用いられ、一つはデータ、左の子、右の子を持った3-tupleのノードで、もう一つはデータも関数ももたない「葉」である(上記PascalやCのようなポインタ型をもった言語の nil に当たる)
二分木を巡回する方法
しばしば、ある二分木に属する各々のノードを調べる必要が出てくる。ノードを訪れる順番には定番的なものがあり、それぞれ利点がある。
行きがけ順、通りがけ順、帰りがけ順探索
二分木においてはあるノードとその子孫もまた二分木を構成する。これを部分木と呼ぶ。 従って二分木を部分木に分け、再帰を用いて探索する方法は自然である。根を調べてからそれにぶらさがる部分木を調べるのが行きがけ順 (preorder)、部分木を調べてからその根を調べるのが帰りがけ順 (postorder) 、片方の部分木を調べ、根を調べ、次いで反対の部分木を調べるのが通りがけ順 (in-order) である。二分探索木では通りがけ順探索はノードを大きさ順(あるいは大きさの逆順)に調べることになる。
深さ優先探索
奥優先探索ともいう。根からできるだけ遠く、しかも、既に調べたノードの子であるノードから調べていく方法である。一般のグラフと異なりこれまでに訪れたノードを全て記憶しておく必要はない。というのも木には閉路がないからである。行きがけ順、通りがけ順、帰りがけ順探索はすべてこれの特殊な例である。
幅優先探索
深さ優先探索と対照的に、未だに訪れていないノードを、根に近い方から探索する。
二分木の応用

二分探索木
ノードごとに値が割り振られているとする。あるノードの左の子およびその全ての子孫ノードの持つ値はそのノードの値より小さく、右の子及びその全ての子孫ノードの持つ値はそのノードの値より大きくなるように構成した二分木を二分探索木 (binary search tree) という。二分探索木を通りがけ順に探索すると、各ノードの値を大きさ順(あるいは逆順)に得ることができる。
このような木を用いると二分探索は容易になる。目的とする値を x とすると、根から始めて、
- 値が n のノードを見つける
- x = n → あたり
- x > n → 左の部分木を同様に調べる
- x < n → 右の部分木を同様に調べる
という再帰的コーディングが可能である。
平衡二分探索木
二分探索木の検索効率が最高になるのは、木の高さが最低な時で、即ち根から各葉までの高さができるだけ等しくなった場合である。そのような二分探索木を平衡二分探索木と呼ぶ。詳細は平衡二分探索木を参照されたい。
バイナリヒープ
半順序集合を二分木で表現したもので、ヒープ、二分ヒープ、バイナリヒープと呼ぶ。親子の間で、割り当てられた値について 親 ≤ 子、ないしは 親 ≥ 子の関係が必ず成立するものをいう。前者の場合根が最小の値、後者の場合、根が最大の値をもつことになる。詳細はヒープや二分ヒープを参照されたい。
算術式の構文木

図の例では、二項演算子を用いた算術式を二分木で表現している。この式を逆ポーランド記法、中置記法、ポーランド記法で記述すると、それぞれ
- a b + c d - × e f + ÷
- (a + b) × (c - d) ÷ (e + f)
- ÷ × + a b - c d + e f
となり、左優先の帰りがけ順、通りがけ順、行きがけ順に相当する。強調部分は図で点線で囲った部分木である。部分木が二分木であることは、式の項もまた式であることとよく対応する。
二分木構造のエンコーディング法
簡潔符号化
簡潔データ構造は情報理論で求められる最小の領域のみを消費するデータ構造である。個のノードを持つ異なった二分木の個数は、即ち番目のカタラン数である(構造が同じ木は同一のものと見なす)。が十分大きくなると、これは程度になる。従って、それらを符号化するには少なくとも bit 程度が必要となる。よって、簡潔二分木はノードあたり 2bit だけを消費するものでなければならない。




この条件を満たす簡単な表現法は、行きがけ順にノードを舐め、内部ノードなら1、葉なら0を出力する方法である(ここで「葉」はデータを含まないものを指す)。木にデータが含まれるなら(例えば前記のPascalの例で、dataフィールドの中身が空でないなら)、それらを次々に配列の中に格納していけばいい。[1] 次のような関数を用いる:
function EncodeSuccinct(node n, bitstring structure, array data) {
if (n = nil) then
structure の最後に 0 を追加する
else
structure の最後に 1 を追加する
data の最後に n.data を追加する
EncodeSuccinct(n.left, structure, data)
EncodeSuccinct(n.right, structure, data)
}
string型データ structure は最終的に bit になるにすぎない。ここで は内部ノードの数である。structure型データの長さすら記録する必要がない。次の関数を実行すれば、情報が全く失われていないことがわかるだろう。これはstring型データから二分木を再構築する:

function DecodeSuccinct(bitstring structure, array data) {
structure の最初のビットを取り除き、そのビットを b に入れる
if ( b = 1 ) then
新しいノード n を作る
dataの最初の要素を取り除き、その要素を n.data に入れる
n.left = DecodeSuccinct(structure, data)
n.right = DecodeSuccinct(structure, data)
n を返す
else
nil を返す
}
更に洗練された簡潔表現を用いると、木構造をより小さく表現できるだけでなく、簡潔さを保ったまま、より便利な操作もできるようになる。
N進木の二分木表現
一般に順序のある木 (ordered tree) と二分木との間に一対一対応関係をつけることができる。これはLISP言語で特に用いられるものである。順序木の中の任意のノードNを二分木のノードnと対応させる。nの左の子はNの最初の子である。Nの次の子はnの右の子m、その次のNの子はmの左の子、そのまた次のNの子はmの右の子、といった様に、次々に右に木を生やしていけばいい。
別の見方をすれば、これは順序木の各ノードの兄弟を次々に「右」フィールドを用いて連結した一種の連結リスト構造に格納し、最初の要素を「左」フィールドに入れたのと同じである。
{B,C,D,E,F,G}の6つの子を持つA(左)を二分木(右)で表現した例である。
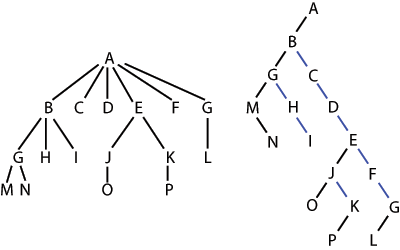
二分木はオリジナルの木を斜に傾けて表現したと考えることもできる。左の黒い辺が「最初の子」、右の青い辺が「次の兄弟」を表す。左の木にある葉はLISPでは
- (((M N) H I) C D ((O) (P)) F (L))
のように表現されるだろう。これは計算機の中では右のように実装されているはずである。
参考文献
- Donald Knuth. Fundamental Algorithms, Third Edition. Addison-Wesley, 1997. ISBN 0-201-89683-4. Section 2.3, especially subsections 2.3.1–2.3.2 (pp.318–348).
関連項目
| |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| その他 | |||||||||||||||||
| 配列構造(英) | |||||||||||||||||
| リンク構造(英) | |||||||||||||||||
| 検索構造(英) |
| ||||||||||||||||
| 木構造 |
| ||||||||||||||||
| グラフ構造 | |||||||||||||||||
| 抽象データ型 | |||||||||||||||||
| |||||||||||||||||
木構造 (計算機科学) | |
|---|---|
| 二分木 |
|
| 平衡2分探索木 | |
| B木 | |
| トライ木 | |
| バイナリ空間分割 木(BSP木) | |
| 非二分木 |
|
| 空間データパーティショニング木 |
|
| ヒープ | |
| その他の木構造 |
|
| | |
| 典拠管理データベース: 国立図書館 |
|
|---|



